• Emma Segal-Grossman, Henry Wilkinson, Tessa Walsh, Ilya Kreymer
Self Sign-up
A lot of our work in this release cycle has been focused on our internal tooling to allow you to sign up for our Browsertrix hosted service in a fully automated way, with billing integration via Stripe. You can now sign up to use Browsertrix on your own, choosing from one of our newly offered plans. Once you sign-up, you can always update your subscription from the new “Billing” pane in Org settings, including automatically switching to a different plan as your crawling needs change!
Better Quality Assurance (QA) Stats
In our last release, we introduced our new QA system. In 1.11, we’ve made a few improvements to make the system even more useful.
The QA analysis meters are now updated in real-time as the analysis is running, allowing you to see immediate results on how the analysis going without having to wait for it to check all the pages. This should provide more immediate feedback about the quality of a larger crawl!
We’ve also added a few extra stats that help our image and text comparison meters make a little more sense. If you haven’t noticed anything funky up until now, that’s great, continue on as you were! For the inquisitive folks, explaining this change fully is a little more involved…
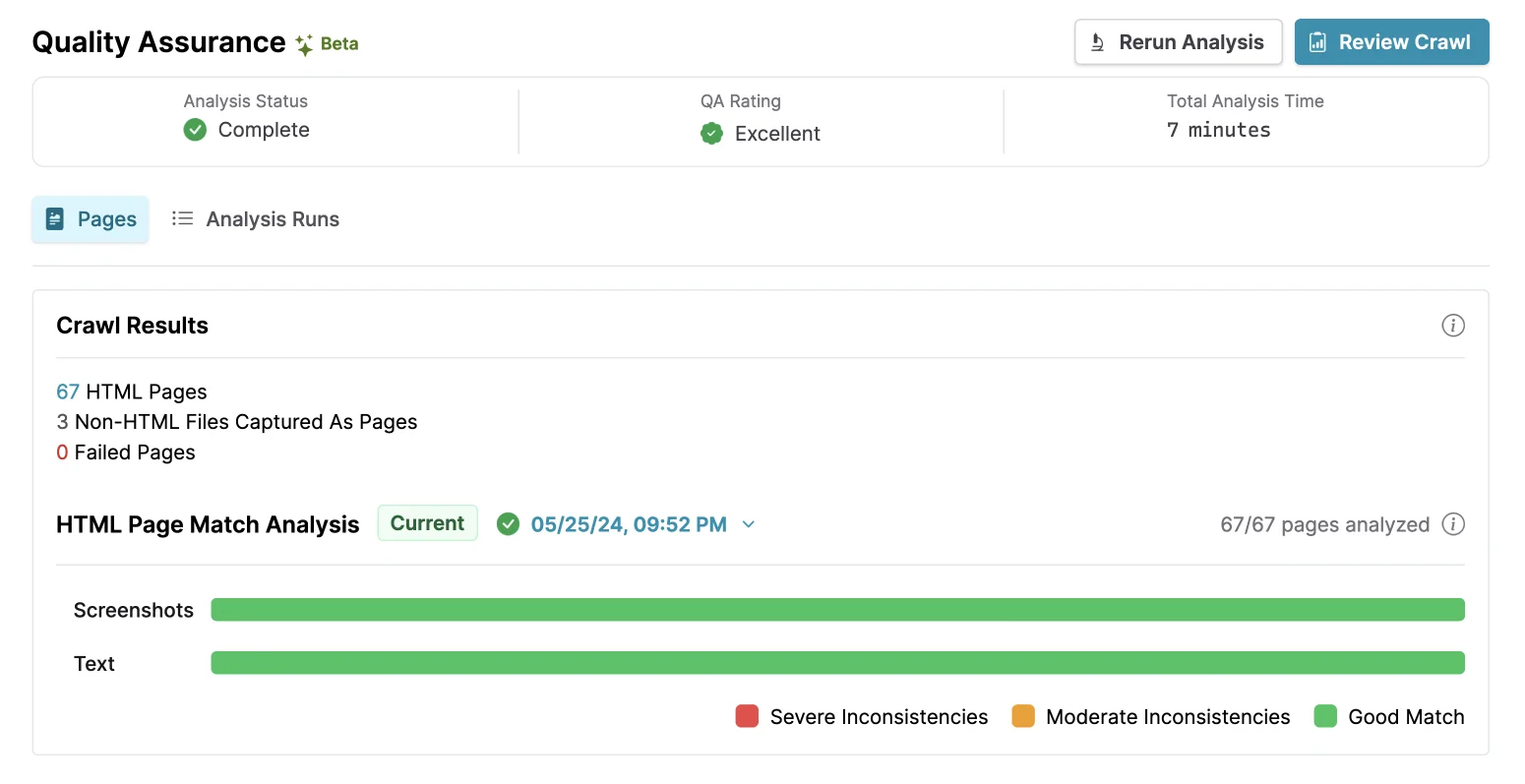
When archiving a website, sometimes the crawler encounters media such as PDFs, images, or video files that are surfaced on pages as links. These are treated as “pages” in the archive because they were linked to like any other HTML page would be (as opposed to being embedded as part of a page) but unlike actual webpages, these “pages” are just static files. Based on this fact, we can say with 100% certainty that, if these files are present within the archive, they’re going to be accurate copies of what was downloaded, and we don’t have to bother assessing them in a QA run, saving you time (and money!)
We’ve never actually run analysis on these files for the reason above, but our bar graph breakdowns didn’t account for this properly and grouped these non-HTML files captured as pages — along with objective failures — in with un-assessed pages, meaning that a 100% complete analysis run might look like it has some un-assessed pages when really they’re just not relevant! In Browsertrix 1.11, we list these above the meters as a separate stat, meaning that the HTML page match analysis graphs should always be fully filled when an analysis run is 100% complete, as it will only display HTML pages that can be analyzed!
Who knew bar graphs could be so involved?!
Easier Archived Item Downloads
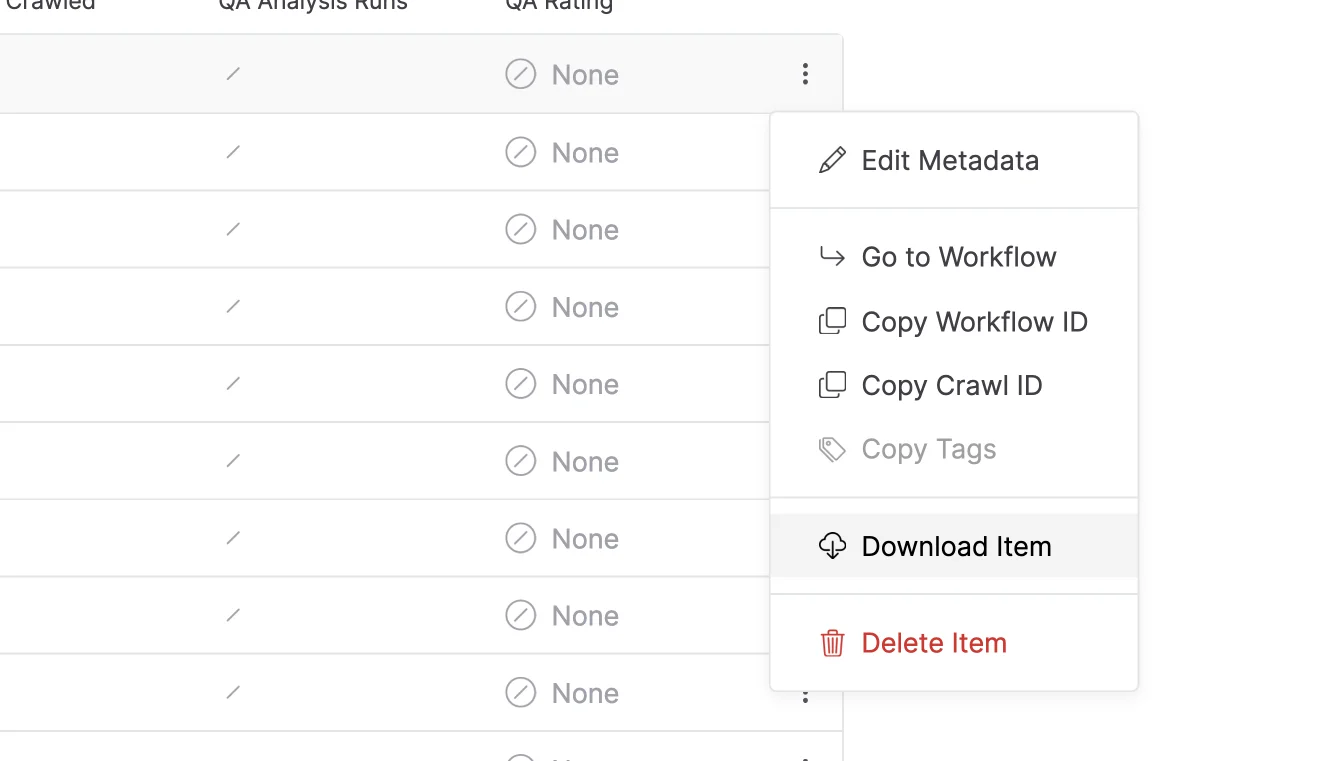
Archived items often contain multiple WACZ files; typically one will be generated for each crawler instance, and they are all split in ~10GB increments. You’ve always been able to download these from the “Files” tab within an archived item’s details page, but we’ve never been satisfied with the amount of clicks required to accomplish this task. Today, that changes! Much like collections, any archived item can now be downloaded with a single click from the actions menu. This packs the associated WACZ files into a single “multi-WACZ” file, which can be replayed in ReplayWeb.page as you’d expect.
Fixes & Small Things
As always, a full list of fixes (and additions) can be found on our GitHub releases page. Here are the highlights:
- If you’re a part of multiple orgs, the list of orgs in the quick switcher is now alphabetically sorted.
- We’ve turned off behaviors for crawl analysis. This greatly reduces the time it takes to run!
Changes for Self-Hosting Users and Developers
While the bulk of the work in this release has been focused on our hosted service, users who are self-hosting Browsertrix can also benefit from a number of improvements to our API and webhooks.
New Webhooks
We now have additional webhooks which can notify when a crawl has been reviewed in the QA process, and when assistive QA analysis has started or finished.
Org Import & Export
Superadmins on self-hosted instances can now export an organization’s data from the database to a JSON file, and import an organization from an exported JSON file into the database. This API-only feature can be used to move organizations from one instance of Browsertrix to another, or to export all information from an organization for backup purposes.
Documentation for org import and export has been added to the Browsertrix deployment documentation.
Org Deletion & Crawling Restrictions
Superadmins on self-hosted instances can now delete orgs. To make sure you know what you’re deleting before you remove it from existence forever, we’ve added a nice verification screen that makes you type in the org name.
Superadmins can also turn off all crawling abilities for an org.
What’s next?
Support for crawling through proxies in different geographic locations and custom storage options for crawling to your own S3 bucket are currently being worked and will be available in a coming release.
To sign up and start crawling with Browsertrix, check out the details at: Browsertrix.com
Have thoughts or comments on this post? Feel free to start a discussion on our forum!