Webrecorder
Web archiving for all!

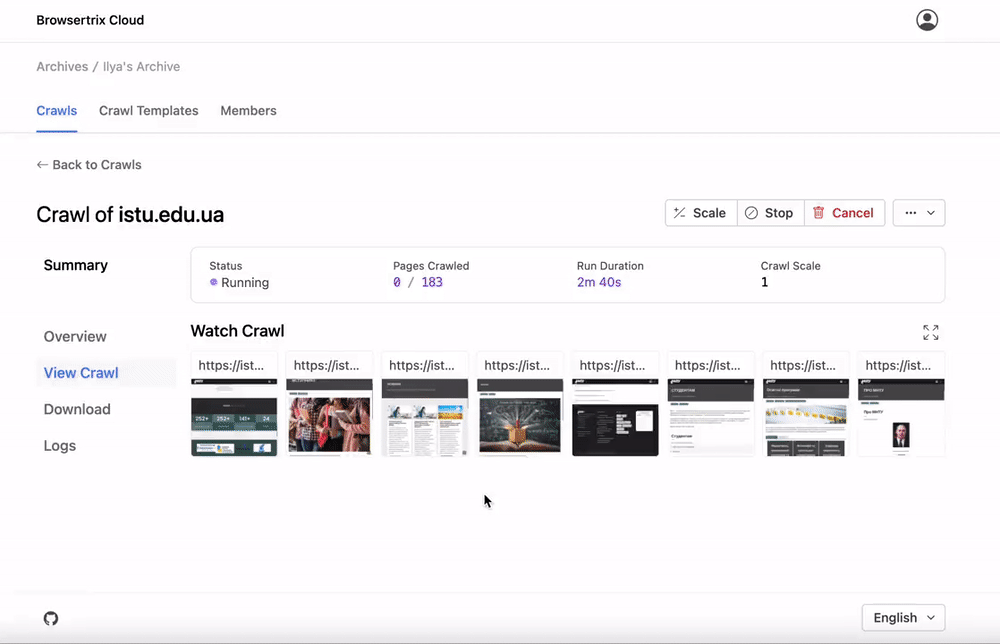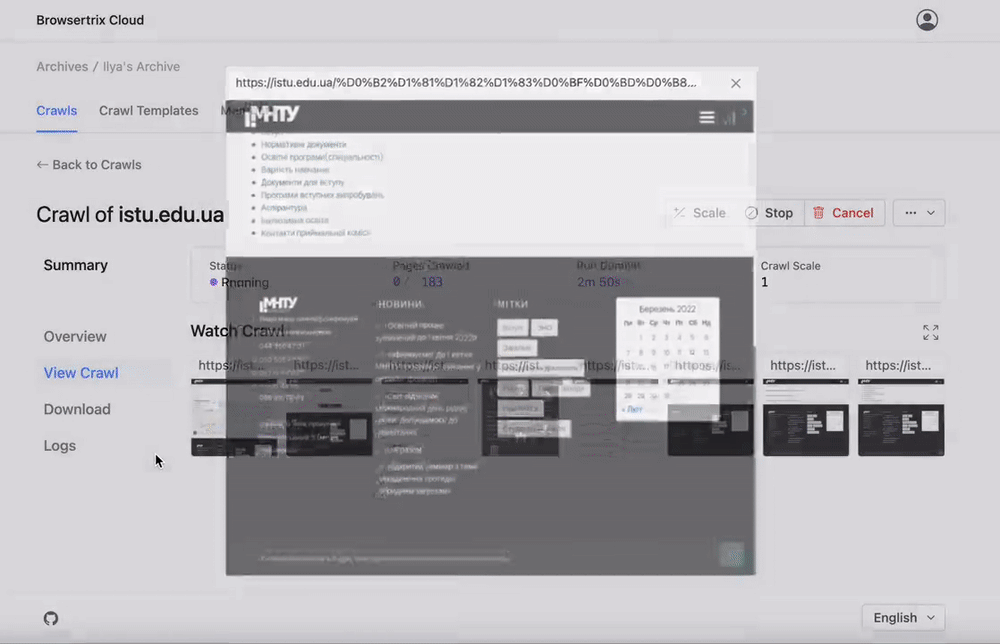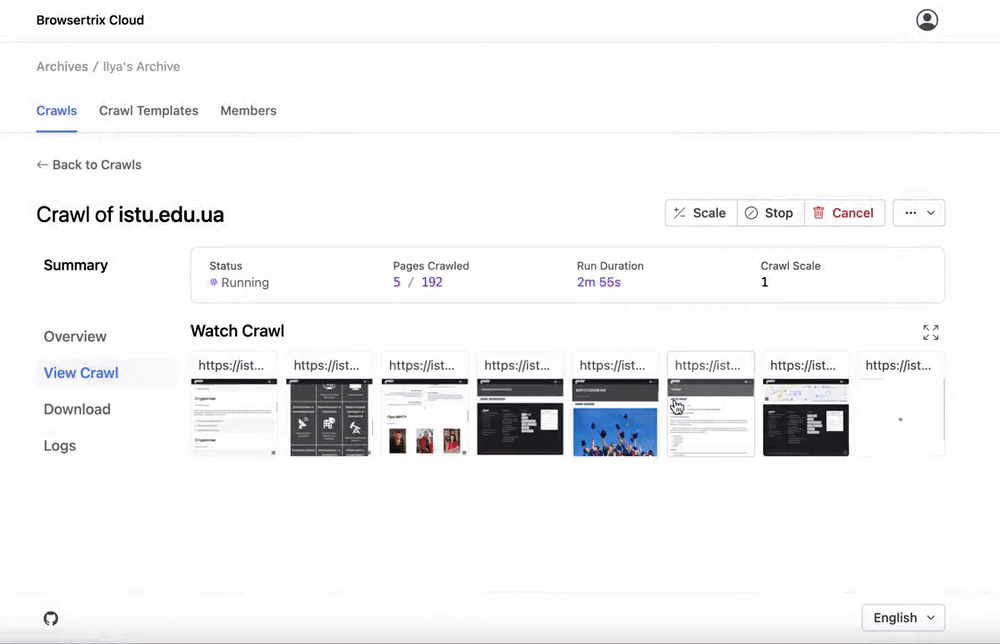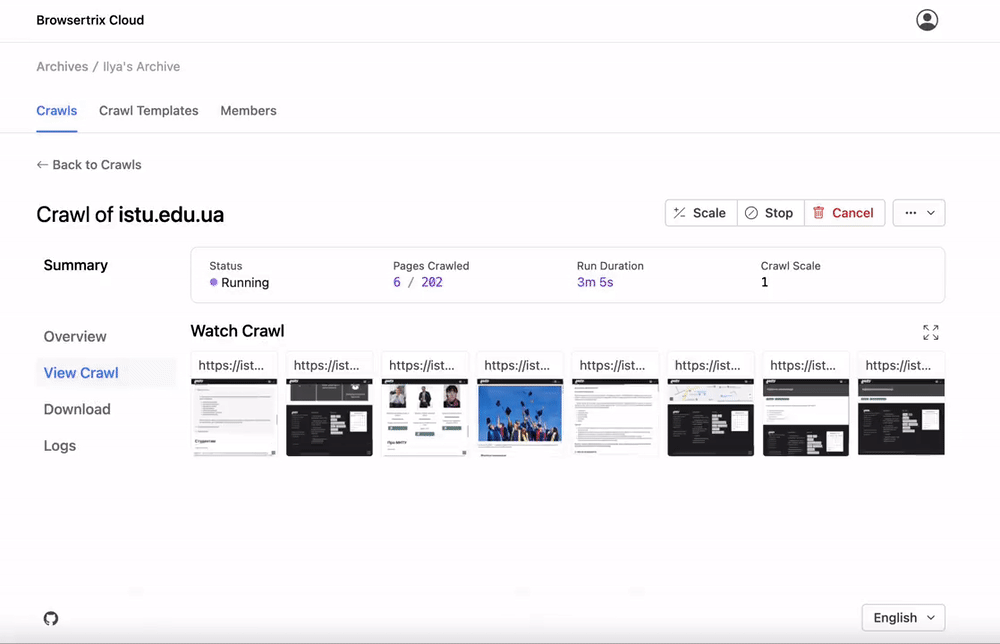




A Chrome extension and desktop app for capturing and replaying pages directly using a browser
A set of automated behaviors for automating interactions with the browser, including generic (playing video, scrolling) and site-specific behaviors, such as for social media
A self-contained crawling system that runs a high-fidelity crawl in a single Docker container
An integrated browser emulation system for running in-browser emulators connected to web archives
The core web archive toolkit, includes web archive replay, access and collection management
Docker Compose based system for running remote browsers (including Flash and Java support) connected to web archives
A set of Docker contains for VNC and WebRTC streaming. A component for pywb-remote-browsers.
A serverless web and desktop app for viewing web archives directly in the browser
A system Docker containiner orchestration system for launch 'flocks' on Docker contains on-demand. Part of the Remote Browser system.
A JS frontend for embedding remote browsers in Conifer. Part of the Remote Browser system
A service-worker based web archive replay system. Backend for ReplayWeb.page
A new specification for a portable Web Archive Collection Zip (WACZ) format and python library
A fast, standalone way to read and write WARC Format commonly used in web archives
A port of python warcio to Javascript. Supports reading/writing WARC files in the browser and in Node.
A command-line tool to convert on-disk directories of web documents (commonly HTML, web assets and any other data files) into an ISO standard web archive (WARC) files.
The client-side rewriting Javascript rewriting system used in pywb and wabac.js