• Henry Wilkinson
After some rest and a few solid weeks of polish after our demo at IIPC’s 2024 Web Archiving Conference, we’re proud to release Browsertrix 1.10: Now with Assistive QA!
Assistive Quality Assurance
Quality assurance for web archives has long been a challenging and time consuming task. The best methods of ensuring a page was captured properly typically fall to a discerning archivist manually scoring various aspects of the page replay to get an overall picture of crawl quality. While we wanted to retain the human element of curation given the vast diversity of the web, our goal in developing these features is to dramatically speed up the review process by providing meaningful heuristics that help direct attention towards pages that need it most.
The crawl analysis and review process is the culmination of these efforts! Browsertrix can now analyze archived webpages by crawling pages from the captured WACZ files and comparing their replay with what the browser saw on the page during the initial crawl — a feature uniquely made possible due to the tight integration of Browsertrix, Browsertrix Crawler, and ReplayWeb.page.
Crawl Analysis
After crawling has completed, the first step in the review process is conducting an analysis run for the archived item in question. On the crawl’s details page in the Quality Assurance tab, press the Review Crawl button to begin the analysis process.
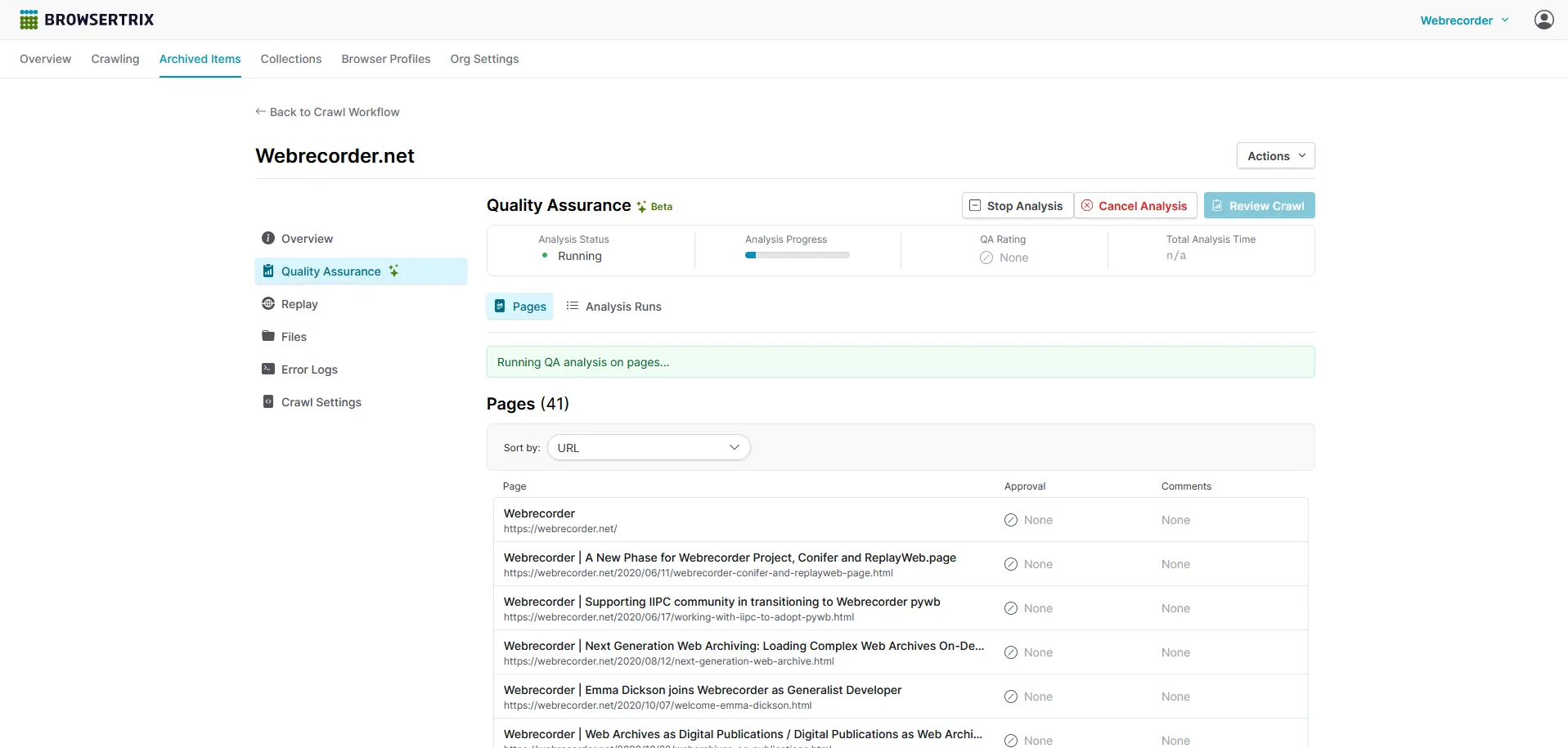
Like crawling, running crawl analysis will also use execution time. While we would generally recommend sticking it out and letting analysis runs complete to get a full picture of the success of your crawl, there may be some instances (a website with many similar pages that you believe to be captured successfully but still want some evidence that is the case) where a stopped analysis run may be enough to get the data you’re looking for.
Once analysis is complete, Browsertrix graphs the matching scores of two analysis dimensions — screenshot and text match comparison.
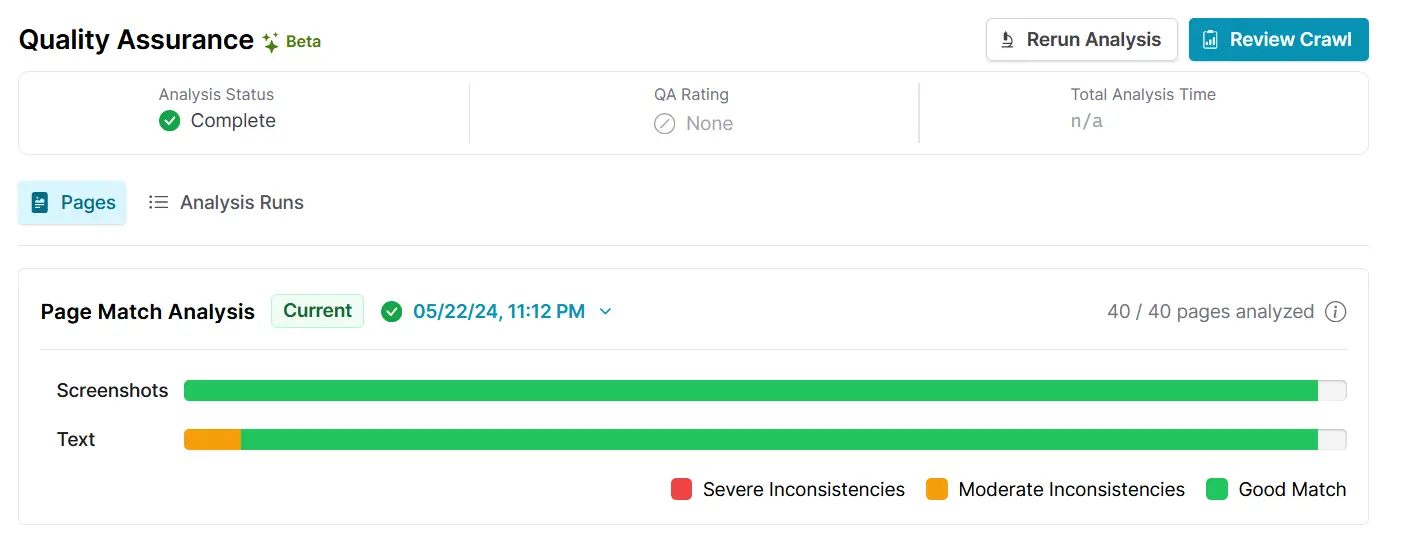
Details on what to expect when re-running crawl analysis can be found in the documentation!
Reviewing Crawls
Now that crawl analysis has finished, let’s take a look at its results in context and decide if our archive is any good! Generally, pages with high scores are less problematic, and you’ll want to direct more attention to pages with lower scores. For an archived item with at least one finished analysis run, pressing the Review Crawl button will open the Crawl Review page.
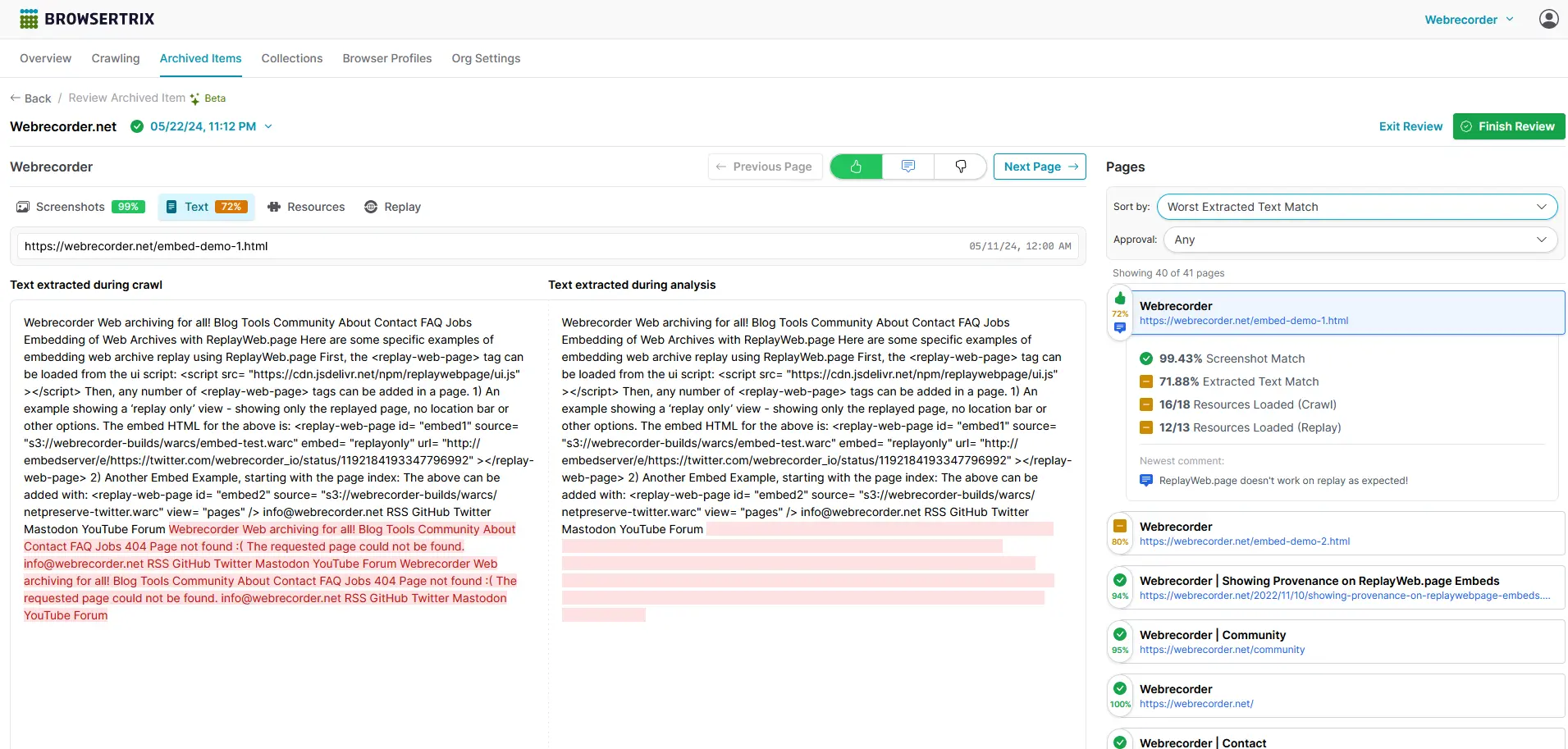
In just a few seconds, we can sort the list of pages by the heuristic we’re interested in (here text comparison) and jump straight to where there might be problems, and indeed there are! Some older ReplayWeb.page embed example pages aren’t loading everything that was found when crawling — in this case it’s because we’re trying to load ReplayWeb.page inside ReplayWeb.page and it doesn’t seem to handle recursive instances of itself very well, a known limitation! This example is pretty specific to our tools and website, some more common text matching discrepencies we’ve encountered are the result of video players’ UI text, cookie & consent popups, embedded content that loaded while archiving but 404s due to a replay issue — any time you see ReplayWeb.page’s “Archived Page Not Found” error show up here there’s probably something worth investigating further!
You can vote the page down and leave a comment if it’s a serious issue you’d like to flag for others, or vote the page up and do the same if the issues aren’t ones you need to worry about. Generally, we wouldn’t recommend assessing and voting on every page; instead, try to assemble a few key examples that exhibit common problems or consistent successes to give other curators concise information about the page quality they can expect from the archived item.
Once you’re satisfied with your assessment of pages, press the Finish Review button to score the success of the entire crawl and update the description with any additional details! This assessment score is reflected in the Archived Items list and will be used elsewhere in the app to assist with organization and discovery in the future.
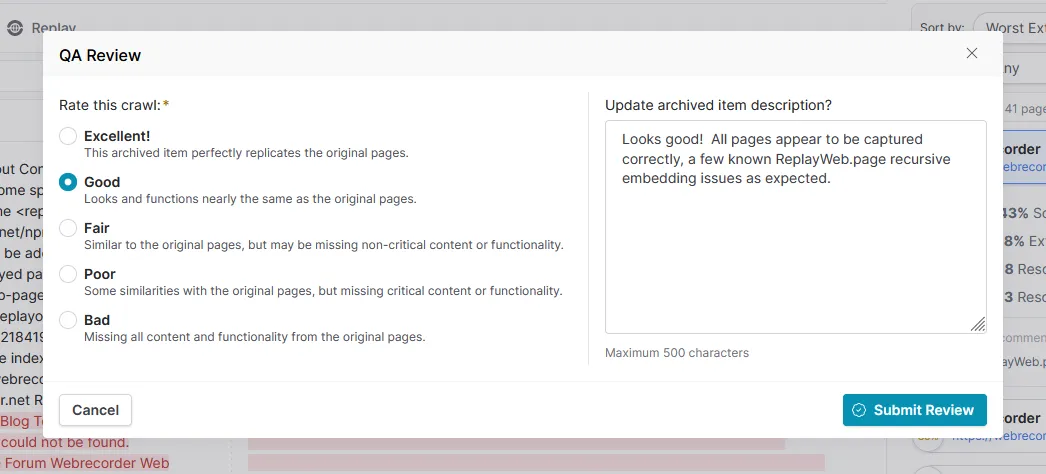
That’s the general process, but it’s not quite everything! The other tabs not covered here allow you to compare screenshots taken while crawling and on replay, a standard replay tab to check the heuristics against the real thing, and a resource comparison table displaying counts of loaded vs unsuccessful page resource fetches. For more information on exactly what you can expect from each heuristic, check out the documentation for crawl analysis!
We’ve been working on this feature since November of 2023 and we’re all very excited to finally get it into your hands! As you might have noticed in the screenshots above, we’re releasing our crawl analysis and review tools with a “beta” tag attached and we’d really like your feedback! Your thoughts are always appreciated on the forum or on GitHub.
Fixes & Small Things
As always, a full list of fixes (and additions) can be found on our GitHub releases page, here are the highlights:
- Browsertrix joins ReplayWeb.page with updated branding! You can see it in the screenshots above, and on this very website!
- Emails are now displayed for both pending and current users in the org settings.
- You can now offset the crawl queue to view URLs from any part of the upcoming pages list.
Changes for Developers
As a key component of Browsertrix, Browsertrix Crawler 1.1+ CLI also supports analysis runs! Running QA with Browsertrix Crawler can also output screenshot diffs to a separate directory for local debugging when using the --qaDebugImageDiff option. Check out our crawler QA documentation and full list of CLI options for more info about this feature.
We have created a Helm repo for Browsertrix! You can add our repository with helm repo add browsertrix https://docs.browsertrix.com/helm-repo/. See our deployment documentation for details.
What’s next?
We’re already hard at work on Browsertrix 1.11 with the beginnings of proxy support and improvements to the heuristic meters above currently in progress. Look for them in the next major release!
If you’re interested in signing up to crawl (and assess the quality of your captures) with Browsertrix, check out the details at: Browsertrix.com
Have thoughts or comments on this post? Feel free to start a discussion on our forum!